
The Interactive Systems Lab at KIT and CMU focuses on technologies that facilitate the human experience, human mutual understanding and communication. Research ranges from speech recognition, translation, speech synthesis, language, vision technologies, person tracking and recognition, multi-modal and cross-modal perceptual interfaces, smart rooms and pervasive computing. Head of the Interactive Systems Lab is Prof. Alex Waibel.
Our laboratory is founding member of interACT. The international center for Advanced Communication Technologies is a joint center between eight of the leading universities in the field of computer science.
NEWS
Rather than artificial intelligence (AI) getting in the way of the human experience, project MeetWeen (My Personal AI Mediator for Virtual MEETtings BetWEEN People) harness’ its power to make human-human interaction more seamless and natural, eliminate language barriers, replace the techno-clutter with support. MeetWeen is EU-funded within Horizon 2020 for a duration of four years.

The Journey of Alex Waibel and the Rise of Spoken Language Translation.
An Overnight Success Story 45 Years in the Making.
More information
Artificial Intelligence was the topic of the summer party of the state representation of Baden-Württemberg in Berlin on July 6, 2023. About 1600 guests visited the event and tried their language skills at the KIT stand. With its “face dubbing system” ISL gave the visitors the possibility to speak in different languages and to see the output on a video.
More information
ISL presented its technology and research at the KIT Open Door Day on June 17, 2023. The public was invited to speak in different languages, in the own voice and with fitting lip movement. ISL was part of the KCIST joint stand –with thousands of visitors it was a great day.
More information
Alex Waibel presented his research during a “Konrad Zuse Lecture” in Hünfeld, Germany on June 16, 2023. He was invited by the “Konrad Zuse Gesellschaft e.V.”, honoring Konrad Zuse who built the first computer more than 70 years ago. Waibel’s lecture was part of the “Hünfelder Gespräche” a high level lecture series.
More informationAlex Waibel received the 2023 James L. Flanagan Speech and Audio Processing Award from the Institute of Electric and Electronic Engineering (IEEE) in recognition of his groundbreaking contributions to spoken language translation and supporting technologies. IEEE selects Flanagan Award recipients based on their impact on the field, innovation, leadership, publications or patents, honors or seminal contributions, and more. Waibel joins a cohort of less than 25 researchers worldwide who have earned this prestigious award since its 2002 inception. He was honored for his achievement on June 6 during the IEEE International Conference on Acoustics, Speech and Signal Processing in Greece.
More information
KIT invited the upcoming students to the “Campustag” on May 13, 2023. ISL showed demos and informed about his research and job opportunities during the whole day.
More informationOn April 20, 2023 US consul general Thatcher Scharpf visited the ISL. He and his delegation received a comprehensive insight by Alex Waibel, into speech technologies and their application.

Alex Waibel will receive the 2023 IEEE James L. Flanagan Speech and Audio Processing Award for his groundbreaking contributions to spoken language translation and supporting technologies.
A professor in Carnegie Mellon University's School of Computer Science has earned a top honor for his decades of work in the field of speech translation.
Alex Waibel will receive the 2023 James L. Flanagan Speech and Audio Processing Award from the Institute of Electric and Electronic Engineering (IEEE) in recognition of his groundbreaking contributions to spoken language translation and supporting technologies.
Further information
Ein internationales Team um das ISL führte im Juli 2022 während einer Expedition in einem U-Boot zum Wrack der Titanic in rund 4 000 Metern Tiefe Tests zu neuen Formen von Videokonferenzsystemen durch. Der Vortrag beschreibt die Forschungsreise in Bildern (Vortrag auf Deutsch, automatisch und simultan übersetzt in verschiedene Sprachen): 06. Feb. 2023, 19.00Uhr, Johann-Gottfried-Tulla-Hörsaal des KIT
Further information
CMU celebrated Raj Reddy's 50+ years at Carnegie Mellon with a lecture on October 14, 2022. Raj is a pioneer in the fields of robotics, artificial intelligence and speech recognition. Among many highlevel speakers (see program) , Alex Waibel honored his doctoral father with a comprehensive Lecture under this link.
Further informationMinister-President Winfried Kretschmann, accompanied by several Ministers, Members of Parliament, Media Representatives, Companies & Start-Ups, Scientists, University Representatives as well as Political Administrators visited Pittsburgh and Carnegie Mellon University beginning of October 2022. Prof. Alex Waibel organized the visit at CMU where Jahanian Farnam, President of CMU welcomed the delegation.
Further information
The Leopoldina and the Korean Academy of Science and Technology (KAST) are working together to increase the mutual visibility of the scientific communities and to intensify the dialogue between academics from both countries. On Sep 29-30 Alex Waibel chaired a joint symposium on the topic: Artificial Intelligence and the Digital Age – Implications for the Future of Society.
Further information
The institute for Anthropomatics and Robotics opened its doors on July 01, 2022 from 3-9pm and gave an insight in its current research. Visitors were able to try the products themselves translate their spoken sentences into different languages. Artificial intelligence and its utilisation were presented in talks by Prof. Tamim Asfour and Prof. Jan Niehues.
Further information
Researchers at Karlsruhe Institute of Technology (KIT) and Carnegie Mellon University (CMU) have developed a method for transmitting video conferences over very low bandwidth connections, enabling such transmissions even under extreme conditions. Alex Waibel now tested the technology during a dive to the wreck of the Titanic, lies at a depth of nearly 4,000 meters in the North Atlantic further information (by CMU).
Further information (by KIT)...Invitation to the lecture given by Marcello Federico, Amazon Web Services, AI lab on Thursday, May 19, 2022 at 3.45-04.30pm (KIT, Bldg. 50.20, room 148). Dr. Federico, principal applied scientist at AWS AI lab, will give an overview on the science work (machine translation, automatic speech dubbing, dialogue systems, and natural language understanding ) on NLP @ AWS AI Labs. He will also present internships and job and funding opportunities for NLP scientists with AWS AI Labs.
Alex Waibel has been elected a fellow of the International Speech Communication Association (ISCA). The ISCA recognized Waibel for his pioneering contributions in multilingual and multimodal spoken language processing and translation. The ISCA fellows program recognizes outstanding members who have made significant contributions to the science and technology of speech communication. Waibel will be honored during the opening ceremony of INTERSPEECH 2022 this September in South Korea.
Further information...
France has taken over the EU-Presidency. One of the mayor events was the "Innovation, Technology and Multilingualism Forum" on February 7-9, 2022. Alex Waibel was invited to give a keynote on "Innovation, Technology and Pluralingualism" - find the entire program here...

Explore our simultaneous automatic translation system in action! Live at KIT's Triangel Open Space on Friday, Oct. 08, 2021 from 10.00am-04.00pm. Further info...

We are proud to announce that our planned event was accepted as official workshop by the IEEE International Conference on Automatic Face and Gesture Recognition 2021, Jodhpur, India (Hybrid Event), to be held on Dec 15 - 18, 2021. The call for paper is now open - have a look, or browse the workshop's web.
Workshop on Face and Gesture Analysis for COVID-19

The US company Zoom Video Communications acquires kites GmbH, a KIT spin-off specializing in the development of real-time machine translation solutions. This was announced by Zoom on 29.06.2021. Zoom will also invest in further research at the Karlsruhe site. kites GmbH is an expert in real-time speech recognition and translation - the team of kites will help to improve Zoom's machine translation.
Pressrelease (in German only)...
The Science Festival "Effekte" is taking place in Karlsruhe from June 12-20, 2021. Part of the Festival is "7 days, seven topics" where one topic of the clubhouse talk is the the revolution of AI - follow the discussion, moderated by Stefan Fuchs (in German only).
Browse the discussion on YouTube
KIT's Annual Celebration, on April 22, 2021 for the first time in a digital format, was translated by our lecture translation service. Further information on the service were provided in the Lecture Translator Lounge.
Browse video: KIT's highlights in 2019 & 2020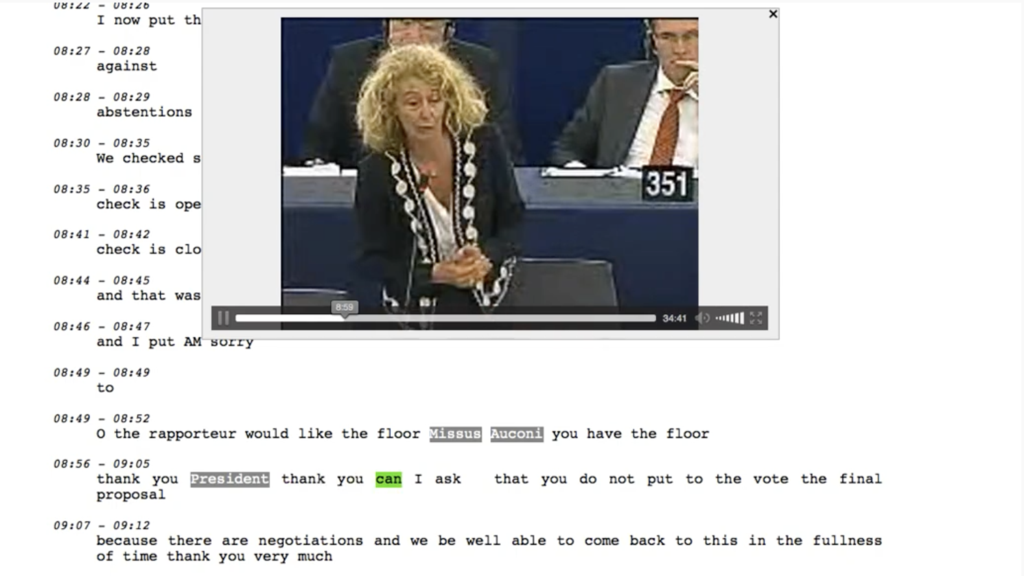
Every week we will present in a short overview video research that was already performed many years ago at ISL. This week: Support tool for translation in the European Parliament, developed during project EU-BRIDGE (2012-15)....
Browse the video on the EP Support Tool
Lectures during the summer term are taking place as planned! Our Lectures will be held via Zoom and are translated in different Languages via our Lecture Translator!
Our Summer term Lectures
ISL wishes all our colleagues, partners and friends a Merry Christmas and a Happy and Healthy New Year 2021!
Look at our projects to pass the timeThe next "International Conference on Spoken Language Translation (IWSLT)" will take place in Bangkok on August 05 & 06, 2021. As in 2020 IWSLT is an official workshop of ACL
Further info...
ISL on TV - browse our hightlights in speech technology in 3Sat-nano...
Go to 3Sat-nano...