First Environment
Creating Architecture Descriptions
Now we have to make a couple of decisions about how the recognizer should look like. We have to decide the following things:
- what topologies and transition probablities to use for HMMs of phonemes
- want to start with simple semicontinuous system or with something better
- how many Gaussians do we want in our mixtures
Since this should be a tiny system to make training easily reproducible and fast, we decide the following:
- The phoneme topology for non-silence phonemes will be:
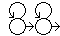
i.e. two states with transitions to themselves and to the next state, the silence and garbage phones will only use one state, all the transitions have equal probability (0.5). - We will start with a continuous densities system, i.e. one codebook for each of the states.
- Every codebook will have sixteen Gaussians, this is a number small enough to be trained awfully fast, and large enough to allow at least a tiny little bit of recognition accuracy.
Let Janus Create its Initial Environment
Creating a first recognizer environment means to create some description files. Although it is possible to not actually create files, but instead reproduce their information on the fly, while Janus is running, this can become rather inconvenient. You can use a pretty simple script for creating all the needed description files:
- phonesSet: A file that contains definitions of sets of phonemes. For the beginning we'll only have one set of our 50 phonemes in there.
- tags: A file listing all the attributes (tags) that a phoneme can have. We will only use the attribute "being at a word boundary".
- transitionModels: A file containing the definition of all possible HMM transition models for a single state.
- topologies: A file containing all possible phoneme HMM topologies. We will only discriminate topolgies for regular phones (two states) and silence/garbage (one state).
- topologyTree: A file containing a context-querying decision tree with questions about the central phone only, and one leaf node for every used phoneme topology.
- featDesc: A file containing a description of how the recordings should be interpreted and preprocessed.
- featAccess: A file containing the definition of how to get the recording files given the information about an utterance from the database.
- codebookSet: A file that contains the description for codebooks, two for each of the phonemes plus one for the silence phone, and one for the garbage phone.
- distribSet: A file that contains the description for mixture-weight distributions; initially there is one distribution for each of the codebooks.
- distribTree: A simple context-querying decision tree with questions about the central phone only, and one leaf node for each of the distributions.
The following script will create all these files. It is establishing the basic objects that are needed and then fills the initially empty datastructures. Eventually all objects and descriptions are written into their files.
On this page the script is split apart to make documentation easier. The complete script which can be run in the "step2" directory directly is here.
This page is meant as a documentation for the script. If you would like to reproduce the results of the script, make sure to do all the commands in the same order as they occur in the script. The description on this page uses a different order.
Let's first define the feature description and feature access rule:
set featDesc {
\$fes readADC ADC \$arg(ADC) -bm shorten -h 0 -offset mean -v 0
\$fes adc2mel MSC ADC 16ms
\$fes meansub MSC MSC -a 2
}
set featAccess {
set adc "adc ../IslData/adcs/$arg(ADC)"; lappend accessList \$adc
}
We've already used a feature description before when we were looking at the recordings. The only difference to the one that we want to use for the recognizer deveolment is a -v 0 flag at the readADC command, which turns verbosity off, and an additional preprocessing command meansub which is doing a spectral mean subtraction on the MSC feature.
The featAccess string contains a rule which states that, whenever we want the adc of an utterance (and we do want that in the first line of the feature description), then we can get it at ../data/recordings/\$arg(ADC) by instantiating \$arg(ADC) with its current value. If you look at the previously created database you will find a field which contains "ADC" followed by the utterance adc path, this is the value that will be used here.
There are no methods offered by the feature module to write description or access files, so we'll have to do it ourselves:
set fp [open featDesc w] ; puts \$fp \$featDesc ; close
\$fp set fp [open featAccess w] ; puts \$fp \$featAccess ; close \$fp
Now, we will create all the needed basic Janus objects:
DistribSet dss [CodebookSet cbs [FeatureSet fs]]
This command creates three objects, namely a feature set named fs a codebook set named cbs, and a distribution set named dss. The Tcl-result of a creatiion command is the name of the object, such that it can be used as an argument for another command, which itself can be a creation command. This way, we can easily do operations on the newly created object in the same script line. The above line, could also have been written like:
FeatureSet fs CodebookSet cbs fs DistribSet dss cbs
Next, we'll create the phonemes and tags:
[PhonesSet ps] add PHONES A AEH AH AI AU B CH D E E2 EH ER2 EU F G H +hBR +hEH +hEM +hGH I IE J K L M N NG \
+nGN O OE OEH OH P +QK R S SCH T TS U UE UEH UH V X Z SIL +
[Tags tags] add WB
You've seen the phonemes before when working on the dictionary. We are using "SIL" for the silence phone and the "+" for the garbage phone. Additionally we have some noise models, indicated by a "+" and an abreviation (for example hBR for BREATH noise). Janus can handle phone names of any length, they do not have to be only one character long.
The tags object contains only one tag, named WB, which is used to mark the phonemes at word boundaries.
Here too, we have used the nice feature to treat the result of an object's creation like the object itself.
Next, we will create a senone set. A senone set needs one or more stream objects. In our case we use only one distribution stream named str. The stream object itself needs a model-set object (in our case it is the distribution set dss) and a tree object, which we call dst. The tree object needs a phones object, a tags object, and a model-set object. Here is the Janus command to create these three beasts:
SenoneSet sns [DistribStream str dss [Tree dst ps:PHONES ps tags dss]]
We called dss a model-set object, knowing that it actually is a distribution set. The term "model-set" is used for any kind of object that complies with the model-set specification. A model-set must offer a minimum of operations to make it a model set. Besides distribution sets, also topology-sets are model-sets. There are others, too, but we'll not discuss that here.
At this point we have to first add all models to the distribution tree, the distribution set and the codebook set, before we can continue to create the topology-related objects. We will discuss this later and continue the description of the script as if the model-adding loop (foreach mod \$modelList ...) was already done.
Now, let's create and fill everything that has to do with HMM topologies:
[TmSet tms] add two {{0 0.7} {1 0.7}}
[TopoSet tps sns tms] add NONSIL {ROOT-b ROOT-e} {two two}
tps add SIL {ROOT-m} {two}
[Tree tpt ps:phones ps tags tps] add ROOT {0=SIL | 0=+} NONSIL SIL - -
tpt add NONSIL {} - - - NONSIL
tpt add SIL {} - - - SIL
Here, we have created a transition model set tms and have given it one transition model, named two, which has two transitions, one jumping 0 states (i.e. remaining in the same state), and one jumping one state (i.e. going to the next state). Both thransitions have a penalty of 0.7 This value is interpreted as the -log of the transition probability. So we are using a transition probability of exp(-0.7) which is approximately 0.5. In our case we could have used any value here. It wouldn't make a difference, as long as both penalties are equal.
After that we've create a topology set named tps. We have defined two topolgies, one named NONSIL and one named SIL. The NONSIL topology has two states (both use the transition model named two), the first one will be acsoustically modeled with beginning segments and the second state with ending phoneme segements, that's why they are marked with ROOT-b and ROOT-e. These root-names will be used by the distribution decision tree as a starting point for descent. The second topology has only one state.
The usage of the toplogies is defined in the topology tree named tpt. It has three nodes, one called ROOT, one called NONSIL and one called SIL. It is a decision tree. The decision made in the root node is based on the question "{0=SIL | 0=+}" which means "is phoneme context zero a silence (SIL) or a garbage (+)". If the answer is "no" then we will proceed with the successor node "NONSIL" otherwise we will proceed with the node "SIL". Don't get confused, the question is not a question whose answer is "silence" or "garbage" the answer is "yes" or "no". Remember that phoneme context 0 means the phoneme itself.
Now that all objects are created, we still need to make us some codebooks and distributions, and we'll have to grow a distribution tree, which is still empty by now. Let's first define a list of all acoustic units that we want to model:
set modelList {
{A b}{AEH b}{AH b}{AI b}{AU b}{B b}{CH b}{D b}{E b}{E2 b}{EH b}{ER2 b}{EU b}{F b}{G b}{H b}
{+hBR b}{+hEH b}{+hEM b}{+hGH b}{I b}{IE b}{J b}{K b}{L b}{M b}{N b}{NG b}{+nGN b}{O b}
{OE b}{OEH b}{OH b}{P b}{+QK b}{R b}{S b}{SCH b}{SIL m}{T b}{TS b}{U b}{UE b}{UEH b}{UH b}
{V b}{X b}{Z b}{+ m} {A e}{AEH e}{AH e}{AI e}{AU e}{B e}{CH e}{D e}{E e}{E2 e}{EH e}{ER2 e}{EU e}
{F e}{G e}{H e}{I e}{IE e}{J e}{K e}{L e}{M e}{N e}{NG e}{O e}{OE e}{OEH e}{OH e}{P e}{R e}{S e}{SCH e}
{T e}{TS e}{U e}{UE e}{UEH e}{UH e}{V e}{X e}{Z e}
}
This list contains two-element lists, each of which contains the name of a phone and the sub-phone segment ID. If we had a function called addModel which would grow the distribution tree accordingly and which would create a single distribution and a single codebook, and configure these objects appropriately after giving it one of these two element lists, then all we would need is to run a loop like this:
foreach mod \$modelList { eval addModel \$mod LDA 48 32 DIAGONAL cbs dss dst }
Unfortunately such a function is not built into Janus. But then again, it is not difficult to write. It can look like this:
proc addModel { phone subTree feature refN dimN type cbs dss tree } {
set dsname \$phone-\$subTree
set question 0=\$phone
set cbname \$phone-\$subTree
set root ROOT-\$subTree
}
Up to this point, we have composed the name of the distribution, the name of the codebook, the question about the central phone, and the name of the root-node from which we will do the descent.
if {[\$cbs index \$cbname] < 0} { \$cbs add \$cbname \$feature \$refN \$dimN \$type }
if {[\$dss index \$dsname] < 0} { \$dss add \$dsname \$cbname }
Creating a codebook and a distribution was easy. Now comes the more complicated stuff, namely growing the tree. Remember that we use "hook" nodes and leaf nodes. The hook nodes are used for asking questions and selecting a successor node. The successor node can be a hook node itself (one to which other nodes are hooked), or it can be a leaf node, in which case there is no question and no successor. A leaf node should have a model (in our case a distribution) associated to it.
So what we are going to do now is do design a new hook node and a new leaf node for the new model to be added to our system:
set qnode hook-\$dsname set lnode \$dsname
Now that the names of these nodes are defined, let's find a place in the tree where to put them. As long as the tree is still context independent, it looks rather simple, every hook node's yes-successor is a leaf node, and every no-successor is another hook-node (except for the root node and the very last no-successor node which has no successors at all). So finding a suitable place for the new model's hook node can be done by descending the tree, following the no-successors, until there is non left, i.e. until we've reached the bottom of the tree. If we find out, that our desired root node does not exist, then we'll have to add that one first before starting the descent:
if {[\$tree index \$root] < 0} {
\$tree add \$root {} \$qnode \$qnode \$qnode "-"
\$tree add \$qnode \$question - \$lnode - -
\$tree add \$lnode {} - - - \$dsname
} else {
\$tree add \$qnode \$question - \$lnode - -
\$tree add \$lnode {} - - - \$dsname
set lidx [\$tree index \$root]
set idx \$lidx
while { [set idx [\$tree.item(\$lidx) configure -no]] > -1} { set lidx \$idx }
\$tree.item(\$lidx) configure -no [\$tree index \$qnode]
}
}
The if statement checks for the exitence of the root node. If it does not exist, we are creating one, including its only successor, the hook node of the new model, succeeded by the model's leaf node.
If the root node does already exist, then we add the two new nodes, follow the no-successors in the while-loop, until we reach the bottom. There we assing our new hook node to be the no-successor of the so far deepest hook node.
The following graphical sequence will visualise the tree growing:
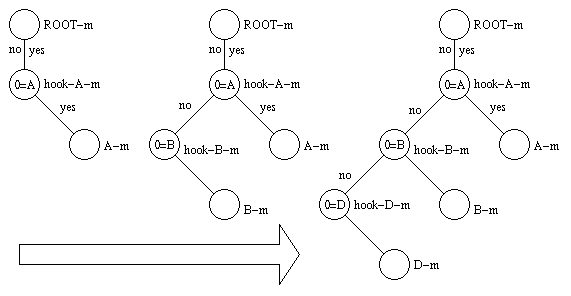
The three displayed phases show the state of the tree after each of the following three addModel calls:
addModel A m MSC 16 16 DIAGONAL cbs dss dst addModel B m MSC 16 16 DIAGONAL cbs dss dst addModel D m MSC 16 16 DIAGONAL cbs dss dst
One more thing is missing. Now that we have created all those objects, we have to write their description files, which is as easy as this:
cbs write codebookSet dss write distribSet dst write distribTree tms write transitionModels tps write topologies tpt write topologyTree ps write phonesSet tags write tags