Acoustic Score Computation
This page does not explain how you as a user should work with Janus. It just describes the entire process of computing an acoustic score for a given part of speech. It is meant to fill some meaning into some terminology and to give you some orientation when reading the rest of the tutorial.
From the Transcription to the HMM
Say, we have a sentence where somebody said "HALLO WORLD". Now we would like Janus to compute the -log of the probability (called score) that at some time t the speaker was just speaking the final portion of the O in the word HALLO. The procedure that we describe now is based on the training process, the testing process is very similar.
When Janus has to build an HMM from a sentences it will first build a word graph. This is a graph which has words in its vertices and transitions between words in its edges. For the HELLO WORLD example a resulting word graph could look like this:
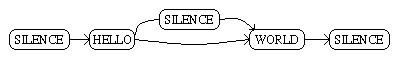
By looking up the words in the pronounciation dictionary, Janus can transform this word graph into a phone graph, whose vertices are phones. Lets say that there are two different possible pronounciations for WORLD, say W E R L D or W E R L T. Then the resulting phone graph would look like this:

From Phonegraph to Stategraph
Now, you know, that a phoneme is usually modeled in multiple states. You can certainly imagine how the corresponding state graph would look like. But once we are down to state level, we have to assign every state an acoustic model. The following picture shows a diagram that shows the entire process and the objects that are involved. Read the diagrams description which follows below.
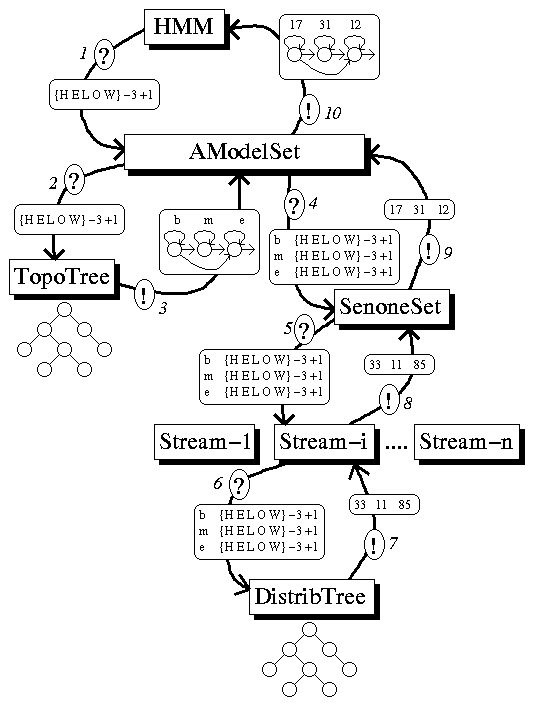
Description of the Diagram
In the above example we wanted the last phone of the word HELLO, we can see that the right context of the O depends on the following word, which can be either SIL or one of WORLD's pronounciation variants. Say we are interested in the acoustic models that we'd have to use in case the following word would be WORLD. Then we'd construct a context description like this:
{H E L O W} -3 +1
indicating that we know the left three-phone contexts H E L and the right one-phone context W. For a couple of reasons we can't use further right context into the next word.
To find out with how many states and what kind of states a phoneme is built and which acoustic models are to be used for it, we have to ask a so called AModelSet which is a Janus object that maintains a list of all possible kinds in which a phoneme can be modeled. The AModelSet itself gets it's information from a SenoneSet object, and a topology tree (a Janus Tree object defined on a TopoSet subobject). When the AModelSet is asked (1) for how to model {H E L O W} -3 +1, it first asks (2) the topology tree about what how many states to use, what transiton model to use for each state, and what kind of acoustic model to use for each state. The answer (3) from the topology tree could be: "Use three states, all three states have one transition to the next state and one selfloop, the first state additionally has a transition to the third state. The first state's acoustic model type is 'b' the second state's type is 'm', the third state's type is 'e'." These model types can be arbitrary strings. We usually use something like 'b' for modeling the beginning third of a phoneme, 'm' for modeling the middle part, and 'e' for modeling the end part of a phoneme. It is very well possible to use only one type for all states, or using very many types, up to one individual type for every state of every context. The do-it-yourself thread describes an example which uses only two different types. These types are actually names of distribution tree nodes, which we will see later.
The HMM-states topology returned by the TopoTree does not need any further information. It can be used directly to build the state-graph. All we still need are the indices of the acoustic models that are used to model each state, we call these models senones. Maybe you've heard about senones already as generalized subtriphones, originally Janus's senones were generalized subtriphones, too. Meanwhile Janus has grown and has got many additional features, such that Janus's senones are more like "acoustic atoms", the smallest acoustic unit that can be scored.
Equipped with the information from the TopoTree the AModelSet, now asks (4) the SenoneSet for how to model a state of a given type in a given context. The SenoneSet object can maintain multiple data-streams, each stream can compute it's score for a given senone, and the final resulting score is a weighted sum of all scores (i.e. the resulting probability is an exponentially weighted product of every stream's probability). Multiple streams can be used for example to model one with Gaussian mixtures and another with neural nets. Then both streams will give their estimates and the result will be a mixture of both. A stream, in Janus, consists of two parts, a descision tree (object class Tree) and a model set (object class can vary, e.g. DistribSet). The decision tree is used to find a single model index for a given context and state-type. The model set is an object that maintains a list of anything that can compute and train acoustic scores. In the case of Gaussian mixtures, these model sets are distribution sets.
The SenoneSet now asks (5) each of its streams for an index that the stream uses to model the given context for the given state type. When different contexts or different state types are modeled with same set of indices then they are also modeled by the same senone. So senones are not just acoustic atoms, they also are unique acustic atoms. No two senones are modeled by the same array of distribution indices.
When a stream is asked for an index it passes this question (6) to the tree (usually a distribution tree). The distribution tree is (as well as the topology tree) a ternary decision tree. In every node of the tree, there is a question about the context. For example: "is the phone that follows the central phone (.i.e context index +1) a vowel?" A node can have up to three sucessors, one if the question is answered with "yes", one for "no", and one for "don't know." In our example this question would have been answered with "no" because the context +1 is the phone W, which is not a vowel. If the question was "is the phone two places to the right of the central phone a consonant?" then the answer would have been "don't know" because in our example the context only goes from -3 to +1, we don't know anything about +2. When the distribution tree is asked for a model index, it descends down the tree, answering questions, until it reaches a leaf node. Every leaf node should have a valid distribution index. This index will be returned (7). In our example we get three answers for three queries. The returned three indices 33, 11, and 85 correspond to the three state types b, m, and e. So far, the distribution tree interpretes the given state types as names of some of its nodes, from where the descent should start.
After every stream has returned its answer (8) to the SenoneSet, the SenoneSet computes a senone index for each set of distribution indices. In our diagram we have only displayed the answer of stream-i, which has returned index 33 for the query "b {H E L O W} -3 +1". Imagine that there were four streams which have all got the same question and the first stream has answered 6, the second 15, the third 33, and the fourth 10, then the quadrupel (6,15,33,10) is converted into a single index, the senone index. Of course, if we use only one stream, which is true in most cases, then there is exactly one senone index for each distribution index. In our case the senone index for the b-type state is 17, for the m-type state 31, and 12 for the e-type state.
When the SenoneSet has computed the senone index it returns it in an answer (9) to the AModelSet, which itself uses it to build its answer (10) to the HMM.
From the Acoustic Model to the Score
Now we do have a complete HMM, a state graph, whose vertices are filled with senone indices. Remember that we wanted to get the -log probability (called score) that at some time t the speaker was just speaking the final portion of the O in the word HALLO. We know by now that the final part of that phone is modeled by a e-type state using the senone with the index 12. We can treat t as an index (we call it frame index) identifying the t-th small window cut out of the entire speech signal. So, what we are looking for is the probability p(t,12) for observing the t-th frame when the senone 12 is uttered.
The following equation shows the class-dependent probability density for observing a vector x given that the senone s was uttered.
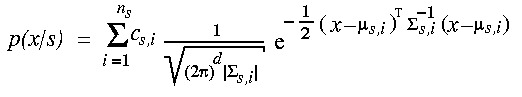
The density is a multivariate Gaussian distribution, also called Gaussian mixture. There are two sets of parameters in there, the mixture weights c and the Gaussian parameters, the means and the covariance matrices. In Janus we call the Gaussian parameters codebooks and the mixture weights distributions. When we are doing parameter tying then the same codebook can be used by different distributions.